

In this 24th episode of the TECHunplugged Podcast we welcome Walter Hinton, Head of Corporate and Product Marketing at Pavilion Data. This episode was recorded live at Dell Technologies World 2019 in Las Vegas.
Podcast co-host Max Mortillaro (@darkkavenger) talks with Walt about the challenges with traditional all-flash infrastructures and the specific needs of modern scale-out applications. Walt covers extensively those topic, then goes on to explain why NVMe-based systems need purpose-built architectures, and how Pavilion Data is a great fit for scale-out / massively parallel applications or filesystems.
About Pavilion Data
Pavilion Data is the industry’s leading NVMe-oF Storage Array. It is a true end-to-end NVMe solution, from the host all the way down to the media. The Array is 100% standards compliant with zero host-side presence and was designed for the modern massively parallel clustered web and analytics applications.
Pavilion’s Storage Array delivers the next generation of composable disaggregated infrastructure (CDI) by separating storage from computing resources to allow them to scale and grow independently. In today’s large-scale environments it allows customers to become more agile by delivering the exact amount of composable resources at any given time.
About Walt
Walt is responsible for Corporate and Product Marketing. He brings a deep technical background along with proven success in building marketing teams and programs. Over a 25-year career in data storage, Walt has helped build successful startups like McDATA, ManagedStorage International and Virident Systems. He also served as Chief Strategist at StorageTek where he was instrumental in the creation of the Storage Network Industry Association (SNIA). Most recently, Walt was Sr. Global Director of Product Marketing at Western Digital. He has a BA from William Jewell College and an MBA from the University of Denver.
Show schedule:
- 00:00 Introduction, Walt’s Presentation
- 02:00 Pavilion Data in numbers
- 02:23 Traditional all-flash array architectures aren’t designed for NVMe because of bottleneck around controllers
- 03:25 Rebuild times in case of a node loss (cca 25 minutes per TB) put a limit to the node capacity of direct attached storage in scale-out storage architectures
- 05:25 Pavilion Data: A storage design inherently built for NVMe: scalable controllers, plenty of networking (40x 100 GbE), a switch-based PCIe backplane, and the ability for customers to source the NVMe drives of their choice
- 06:40 Walt explains that Pavilion Data’s architecture allows for a data rebuild at a rate of 5 minutes per TB
- 07:32 Use cases, industries and verticals for Pavilion Data
- 08:22 The perfect fit for Pavilion Data: scale-out applications leveraging Cassandra, MongoDB, MariaDB etc.
- 08:38 The Pavilion Data – Pivotal partnership – supporting Greenplum (an open-source massively parallel data platform for analytics, machine learning and AI)
- 09:01 A take on financial services, massively distributed databases, and backup challenges with multi-petabyte data lakes
- 10:20 Talking about protocols (Pavilion Data is block-based) and clustered filesystems (Spectrum Scale, etc.)
- 11:41 Continuing the discussion on supercomputing and massively parallel compute, media & entertainment, as well as government
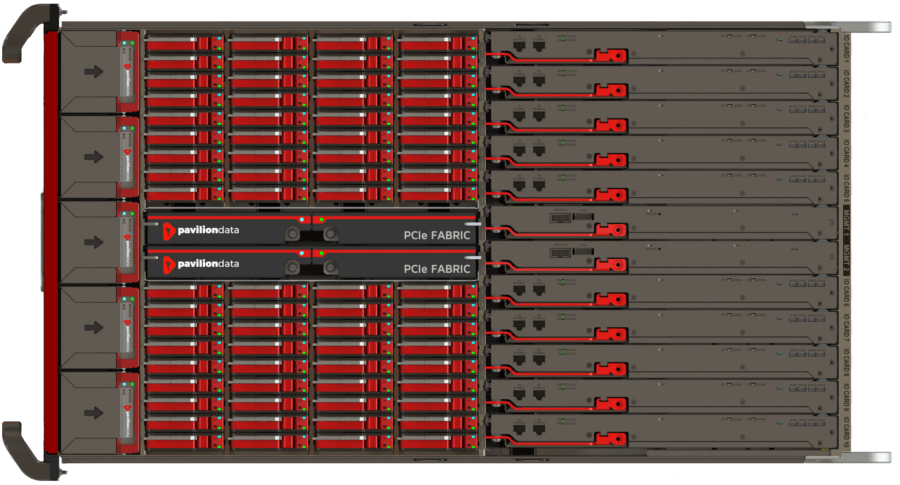
- 13:05 Describing the physical aspects of a Pavilion Data system
- 13:50 A 4U, fully fault-tolerant system achieving 120 Gb/s reads or 90 Gb/s writes – what is the equivalent with a traditional AFA?
- 15:05 The metaphor of the nail and the hammer
- 15:31 Partnerships & Sales – how to engage Pavilion Data
- 16:25 The partnership with Dell
- 17:30 The synergy between Pivotal and Pavilion Data – embracing customer needs
- 19:15 Talking about worldwide availability
- 20:28 Closing remarks
Podcast: Play in new window | Download
Subscribe: Apple Podcasts | RSS | More